集合通信
和P2P通信相对应,集合通信则是1对多或是多对多的。在分布式系统中,各个节点间往往存在大量的集合通信需求,而我们可以用消息传递接口(Message Passing Interface, MPI)来定义一些比较底层的消息通信行为譬如Reduce、Allreduce、Scatter、Gather、Allgather等。常用的通信模式有:
- Broadcast
- Scatter
- Gather
- Reduce
- All reduce
- All gather
AllReduce其实是一类算法,目标是高效得将不同机器中的数据整合(reduce)之后再把结果分发给各个机器。在深度学习应用中,数据往往是一个向量或者矩阵,通常用的整合则有Sum、Max、Min等。
1. broadcast
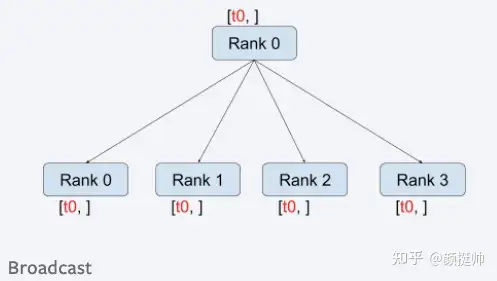
broadcast的计算方式如上图所示。
在pytorch中通过torch.distributed.broadcast(tensor, src, group=None, async_op=False) 来broadcast通信。
- 参数tensor在src rank是input tensor,在其他rank是output tensor;
- 参数src设置哪个rank进行broadcast,默认为rank 0;
使用方式如下面代码所示:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before broadcast',' Rank ', rank_id, ' has data ', tensor)
dist.broadcast(tensor, src = 0)
print('after broadcast',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
输出内容为:
- 一共有4个rank参与了broadcast计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8]
- broadcast计算之后,所有rank的结果均rank0的tensor即[1, 2](因为在调用torch.distributed.broadcast时src设置为0,表示rank0进行broadcast)
before broadcast Rank 1 has data tensor([3, 4])
before broadcast Rank 0 has data tensor([1, 2])
before broadcast Rank 2 has data tensor([5, 6])
before broadcast Rank 3 has data tensor([7, 8])
after broadcast Rank 1 has data tensor([1, 2])
after broadcast Rank 0 has data tensor([1, 2])
after broadcast Rank 2 has data tensor([1, 2])
after broadcast Rank 3 has data tensor([1, 2])
2. scatter
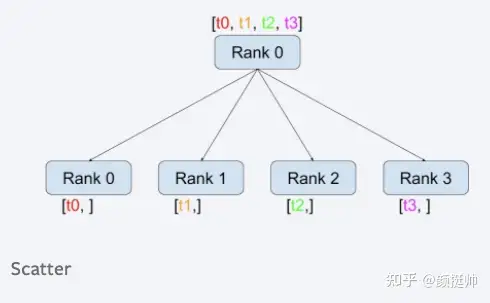
scatter的计算方式如上图所示。
在pytorch中通过torch.distributed.scatter(tensor, scatter_list=None, src=0, group=None, async_op=False) 来实现scatter通信。
- 参数tensor为除 src rank外,其他rank获取output tensor的参数
- scatter_list为进行scatter计算tensor list
- 参数src设置哪个rank进行scatter,默认为rank 0;
使用方式如下面代码所示:
- 这里需要注意的是,仅有src rank才能设置scatter_list( 本例中为rank 0),否则会报错
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before scatter',' Rank ', rank_id, ' has data ', tensor)
if rank_id == 0:
scatter_list = [torch.tensor([0,0]), torch.tensor([1,1]), torch.tensor([2,2]), torch.tensor([3,3])]
print('scater list:', scatter_list)
dist.scatter(tensor, src = 0, scatter_list=scatter_list)
else:
dist.scatter(tensor, src = 0)
print('after scatter',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
输出内容为:
- 一共有4个rank参与了scatter计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8],scatter list为[0,0], [1,1], [2,2], [3,3];
- scatter计算之后,rank按顺序被分配scatter list的每一个tensor, rank0为[0,0], rank1为 [1, 1] , rank2为 [2, 2], rank3[3, 3];
root@g48r13:/workspace/communication# python scatter.py
before scatter Rank 1 has data tensor([3, 4])
before scatter Rank 0 has data tensor([1, 2])
before scatter Rank 2 has data tensor([5, 6])
scater list: [tensor([0, 0]), tensor([1, 1]), tensor([2, 2]), tensor([3, 3])]
before scatter Rank 3 has data tensor([7, 8])
after scatter Rank 1 has data tensor([1, 1])
after scatter Rank 0 has data tensor([0, 0])
after scatter Rank 3 has data tensor([3, 3])
after scatter Rank 2 has data tensor([2, 2])
3. gather
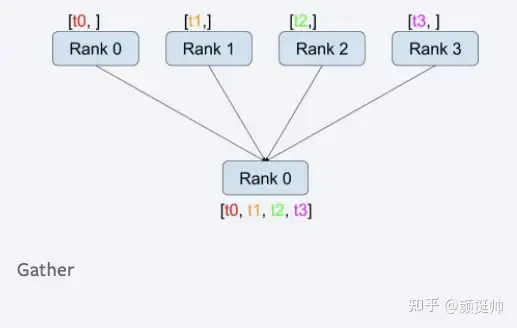
gather计算方式如上图所示。在pytorch中通过torch.distributed.gather(tensor, gather_list=None, dst=0, group=None, async_op=False)来实现gather的通信;
- 参数tensor是所有rank的input tensor
- gather_list是dst rank的output 结果
- dst为目标dst
使用方式如下:
- 这里需要注意的是在rank 0(也就是dst rank)中要指定gather_list,并且要在gather_list构建好的tensor,否是会报错
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before gather',' Rank ', rank_id, ' has data ', tensor)
if rank_id == 0:
gather_list = [torch.zeros(2, dtype=torch.int64) for _ in range(4)]
dist.gather(tensor, dst = 0, gather_list=gather_list)
print('after gather',' Rank ', rank_id, ' has data ', tensor)
print('gather_list:', gather_list)
else:
dist.gather(tensor, dst = 0)
print('after gather',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
输出内容如下:
- 一共有4个rank参与了gather计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8]
- gather计算之后,gather_list的值为[tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
root@g48r13:/workspace/communication# python gather.py
before gather Rank 0 has data tensor([1, 2])
before gather Rank 3 has data tensor([7, 8])
after gather Rank 3 has data tensor([7, 8])
before gather Rank 1 has data tensor([3, 4])
before gather Rank 2 has data tensor([5, 6])
after gather Rank 1 has data tensor([3, 4])
after gather Rank 2 has data tensor([5, 6])
after gather Rank 0 has data tensor([1, 2])
gather_list: [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
4. reduce
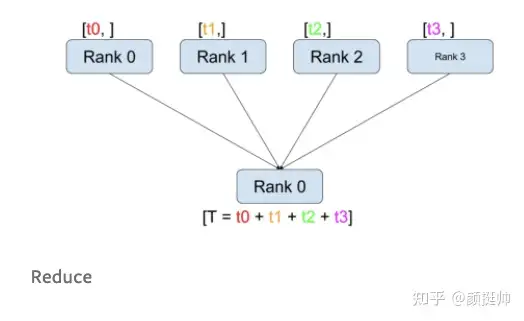
reduce的计算方式如上图所示。在pytorch中通过torch.distributed.reduce(tensor, dst, op=<ReduceOp.SUM: 0>, group=None, async_op=False)来实现reduce通信;
- 参数tensor是需要进行reduce计算的数据,对于dst rank来说,tensor为最终reduce的结果
- 参数dist设置目标rank的ID
- 参数op为reduce的计算方式,pytorch中支持的计算方式有SUM, PRODUCT, MIN, MAX, BAND, BOR, and BXOR
使用方式如下:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before reudce',' Rank ', rank_id, ' has data ', tensor)
dist.reduce(tensor, dst = 3, op=dist.ReduceOp.SUM,)
print('after reudce',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
执行结果如下:
- 一共有4个rank参与了gather计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8];dst rank设置为3
- 可见rank 3为reduce sum计算的最终结果;
- 需要注意这里有个副作用,就是rank 0、rank 1和rank 2的tensor也会被修改
root@g48r13:/workspace/communication# python reduce.py
before reudce Rank 3 has data tensor([7, 8])
before reudce Rank 0 has data tensor([1, 2])
before reudce Rank 2 has data tensor([5, 6])
before reudce Rank 1 has data tensor([3, 4])
after reudce Rank 1 has data tensor([15, 18])
after reudce Rank 0 has data tensor([16, 20])
after reudce Rank 3 has data tensor([16, 20]) # reduce 的最终结果
after reudce Rank 2 has data tensor([12, 14])
5. all-gather
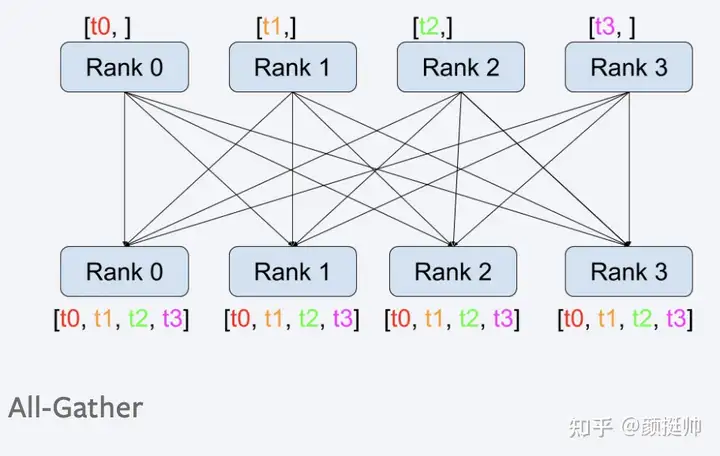
all-gather计算方式如上图所示。在pytorch中通过torch.distributed.all_gather(tensor_list, tensor, group=None, async_op=False)来实现。
- 参数tensor_list,rank从该参数中获取all-gather的结果
- 参数tensor,每个rank参与all-gather计算输入数据
使用方式如下:
- 同gather的使用方式基本一样,区别是all_gather中每个rank都要指定gather_list,并且要在gather_list构建好的tensor,否是会报错;
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before gather',' Rank ', rank_id, ' has data ', tensor)
gather_list = [torch.zeros(2, dtype=torch.int64) for _ in range(4)]
dist.all_gather(gather_list, tensor)
print('after gather',' Rank ', rank_id, ' has data ', tensor)
print('after gather',' Rank ', rank_id, ' has gather list ', gather_list)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
执行结果如下:
- 一共有4个rank参与了gather计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8];
- 执行完gather_list后,每个rank均可以拿到最终gather_list的结果
root@g48r13:/workspace/communication# python all_gather.py
before gather Rank 0 has data tensor([1, 2])
before gather Rank 2 has data tensor([5, 6])
before gather Rank 3 has data tensor([7, 8])
before gather Rank 1 has data tensor([3, 4])
after gather Rank 1 has data tensor([3, 4])
after gather Rank 0 has data tensor([1, 2])
after gather Rank 3 has data tensor([7, 8])
after gather Rank 2 has data tensor([5, 6])
after gather Rank 1 has gather list [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
after gather Rank 0 has gather list [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
after gather Rank 3 has gather list [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
after gather Rank 2 has gather list [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
6. all-reduce
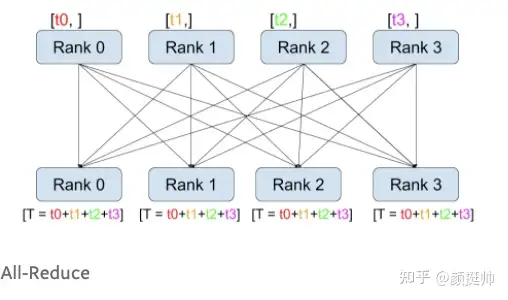
all-reduce计算方式如上图所示。在pytorch中通过torch.distributed.all_reduce(tensor, op=<ReduceOp.SUM: 0>, group=None, async_op=False)来实现all-reduce的调用;
使用方式如下面代码所示
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before reudce',' Rank ', rank_id, ' has data ', tensor)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print('after reudce',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
输出内内容为:
- 一共有4个rank参与了all-reduce计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8]
- all-reduce计算之后,所有rank的结果均相同,为rank0-rank3的tensor计算sum的结果[1+3 + 5 + 7, 2 + 4 + 6 + 8]=[16, 20]
root@g48r13:/workspace/communication# python all_reduce.py
before reudce Rank 3 has data tensor([7, 8])
before reudce Rank 2 has data tensor([5, 6])
before reudce Rank 0 has data tensor([1, 2])
before reudce Rank 1 has data tensor([3, 4])
after reudce Rank 0 has data tensor([16, 20])
after reudce Rank 3 has data tensor([16, 20])
after reudce Rank 2 has data tensor([16, 20])
after reudce Rank 1 has data tensor([16, 20])
参考资料
Pytorch - 分布式通信原语(附源码) - 颜挺帅的文章 - 知乎