Spark运行原理
一、spark相关概念
1.1 Application:Spark应用程序
指的是用户编写的Spark应用程序,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
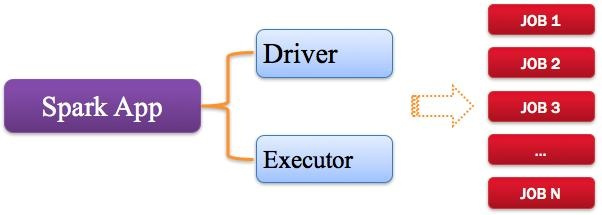
Spark应用程序,由一个或多个作业JOB组成,如下图所示。
1.2 Driver:驱动程序
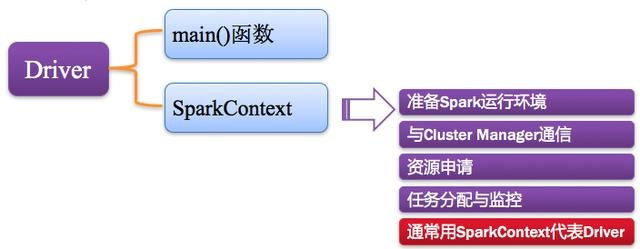
Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常SparkContext代表Driver,如下图所示。
1.3 Cluster Manager:资源管理器
指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Haddop Yarn,由Yarn中的ResearchManager负责资源的分配;Messos,由Messos中的Messos Master负责资源管理。
1.4 Executor:执行器
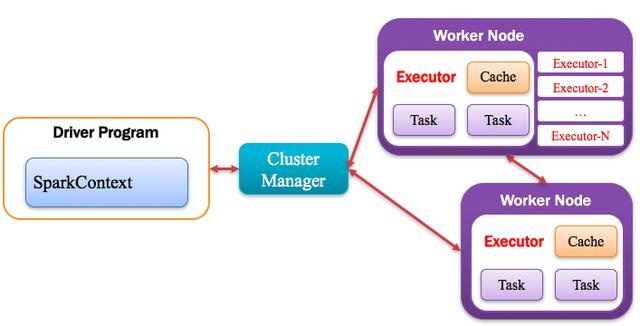
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor,如下图所示。
1.5 Worker:计算节点
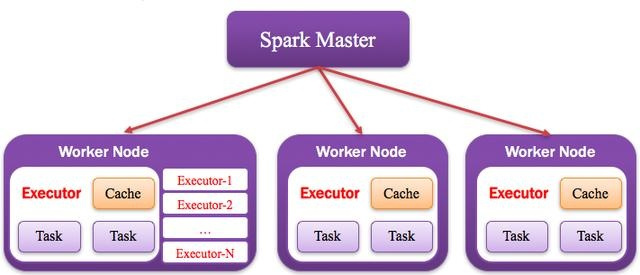
集群中任何可以运行Application代码的节点,类似于Yarn中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点,在Spark on Messos模式中指的就是Messos Slave节点,如下图所示。
二、Spark运行基本流程
当执行一个应用时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其他数据库中。
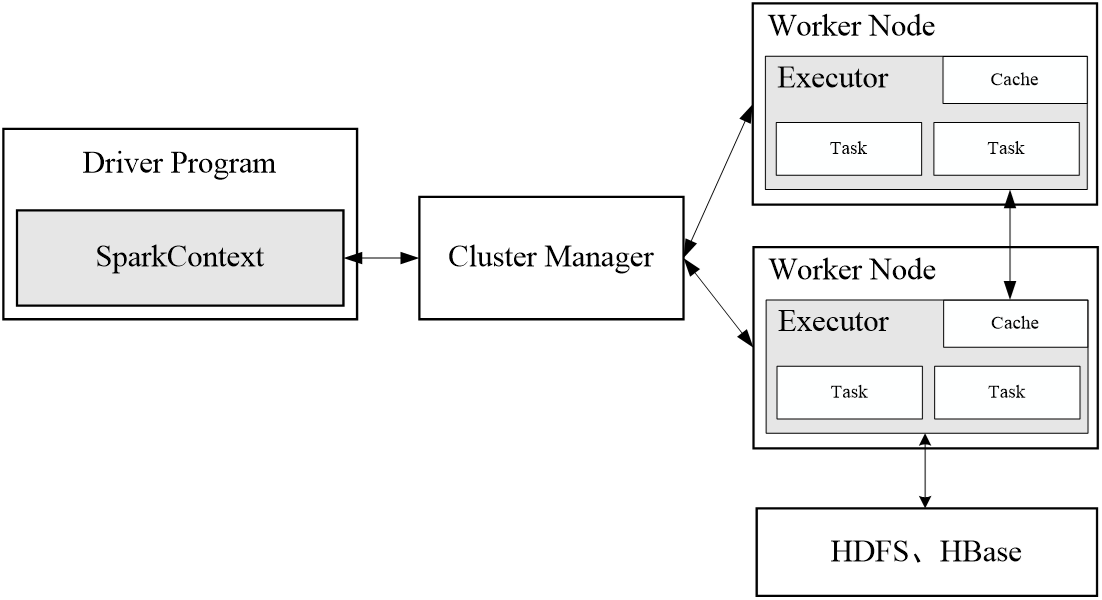
(1)首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控
(2)资源管理器为Executor分配资源,并启动Executor进程
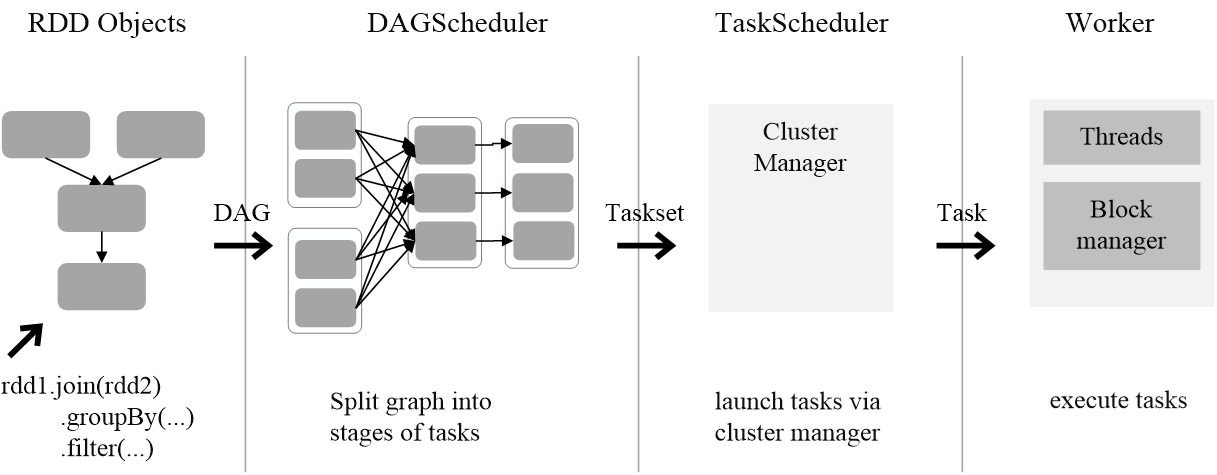
(3)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供应用程序代码
(4)Task在Executor上运行,把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源

三、RDD运行原理
3.1 RDD设计背景
- 许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,共同之处是,不同计算阶段之间会重用中间结果
- 目前的MapReduce框架都是把中间结果写入到稳定存储(比如磁盘)中,带来了大量的数据复制、磁盘IO和序列化开销
- RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储
3.2 RDD(Resillient Distributed Dataset)概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和group by)而创建得到新的RDD
RDD提供了一组丰富的操作以支持常见的数据运算,分为“动作”(Action)和“转换”(Transformation)两种类型
RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改(不适合网页爬虫)
表面上RDD的功能很受限、不够强大,实际上RDD已经被实践证明可以高效地表达许多框架的编程模型(比如MapReduce、SQL、Pregel)
Spark提供了RDD的API,程序员可以通过调用API实现对RDD的各种操作
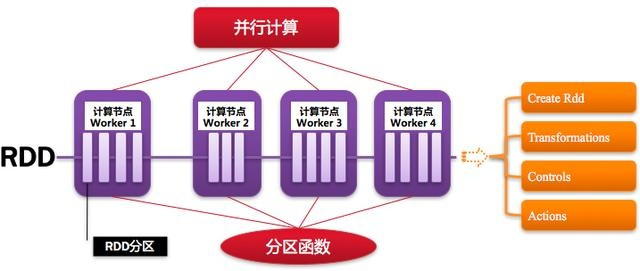
3.3 RDD典型执行过程
- RDD读入外部数据源进行创建
- RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换操作使用
- 最后一个RDD经过“动作”操作进行转换,并输出到外部数据源
这一系列处理称为一个Lineage(血缘关系),即DAG拓扑排序的结果
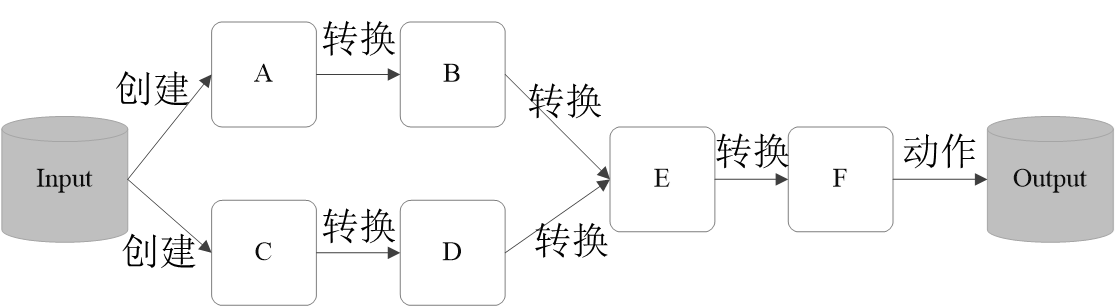
优点:惰性调用、管道化、避免同步等待、不需要保存中间结果、每次操作变得简单
3.3 RDD特性
Spark采用RDD以后能够实现高效计算的原因主要在于:
(1)高效的容错性
现有容错机制:数据复制或者记录日志
RDD:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作
(2)中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
3.4 DAG图阶段划分
3.4.1 窄依赖和宽依赖
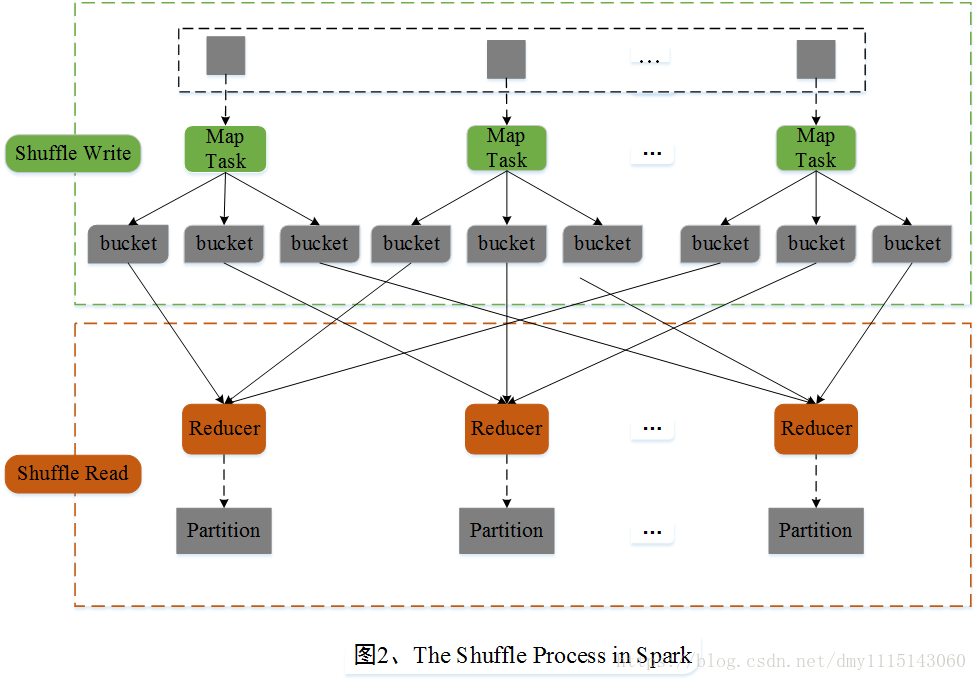
Shuffle操作
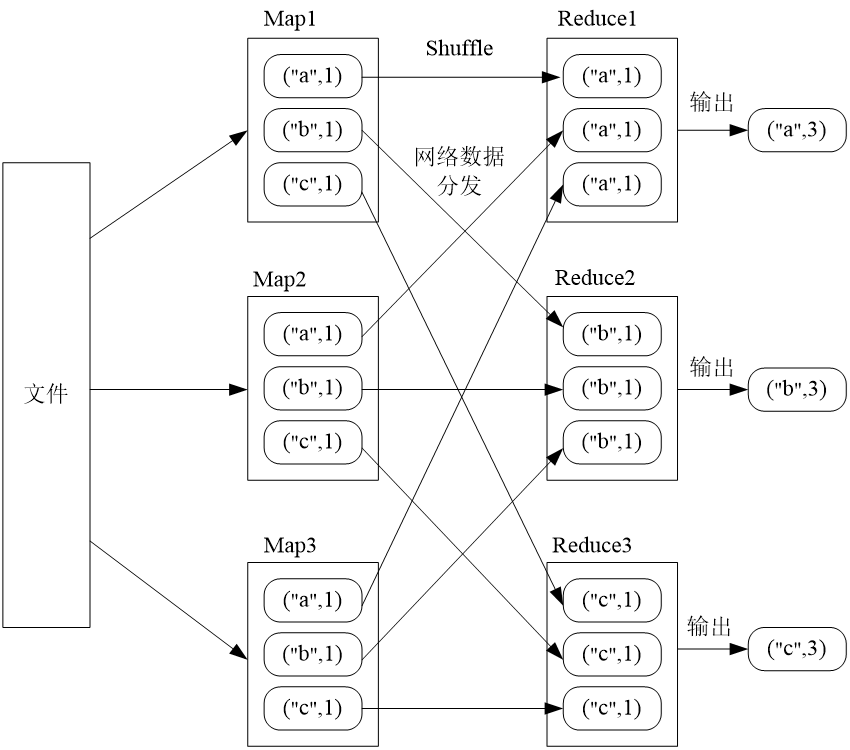
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,如图所示:
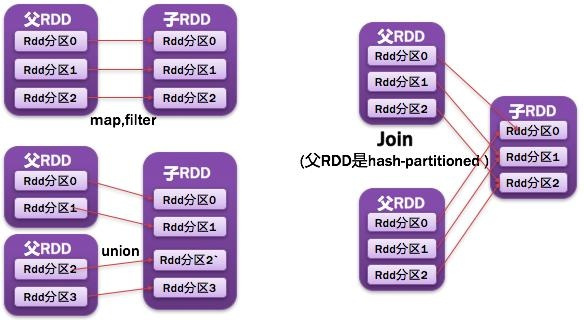
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区
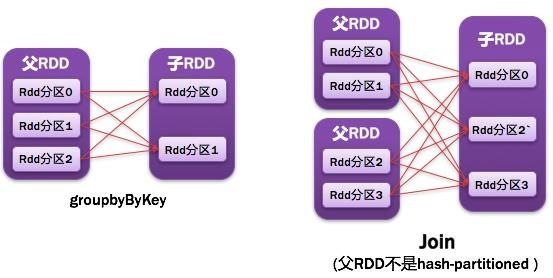
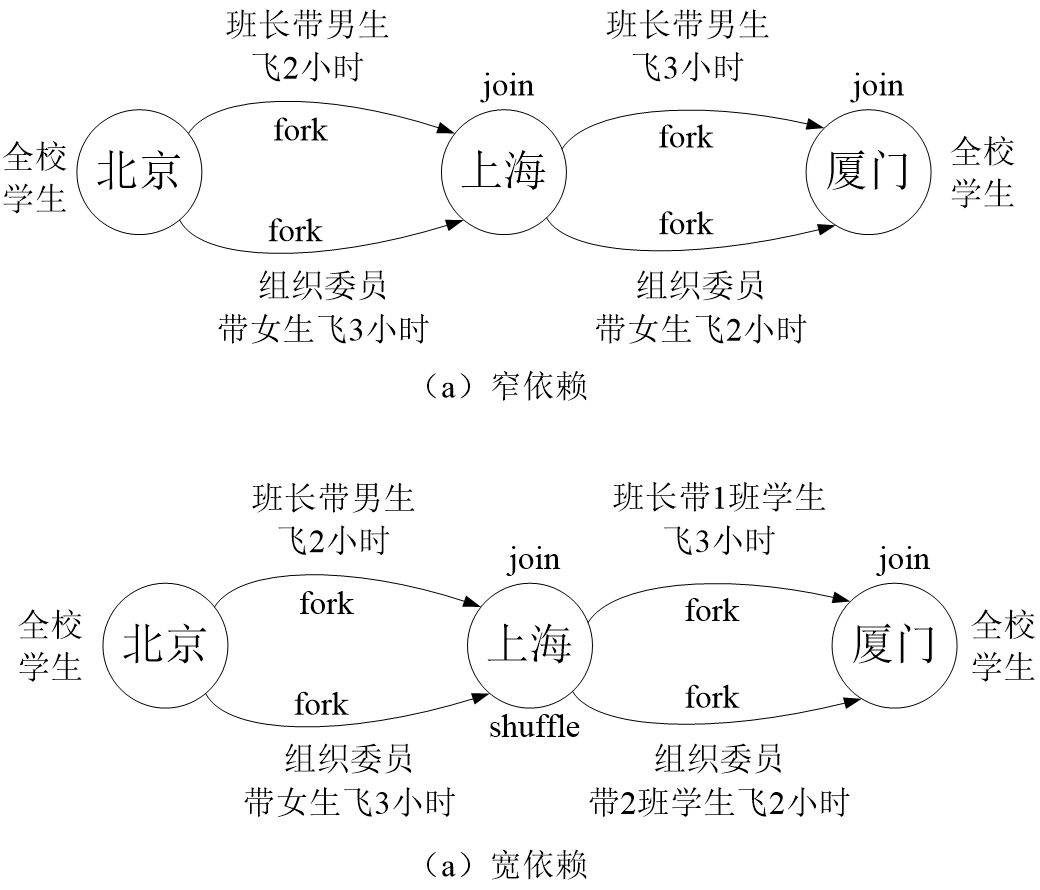
3.4.3 阶段的划分
Spark根据DAG图中的RDD依赖关系,把一个作业分成多个阶段。对于宽依赖和窄依赖而言,窄依赖对于作业的优化很有利。只有窄依赖可以实现流水线优化,宽依赖包含Shuffle过程,无法实现流水线方式处理。举例如图:
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage,具体划分方法是:
- 在DAG中进行反向解析,遇到宽依赖就断开
- 遇到窄依赖就把当前的RDD加入到Stage中
- 将窄依赖尽量划分在同一个Stage中,可以实现流水线计算
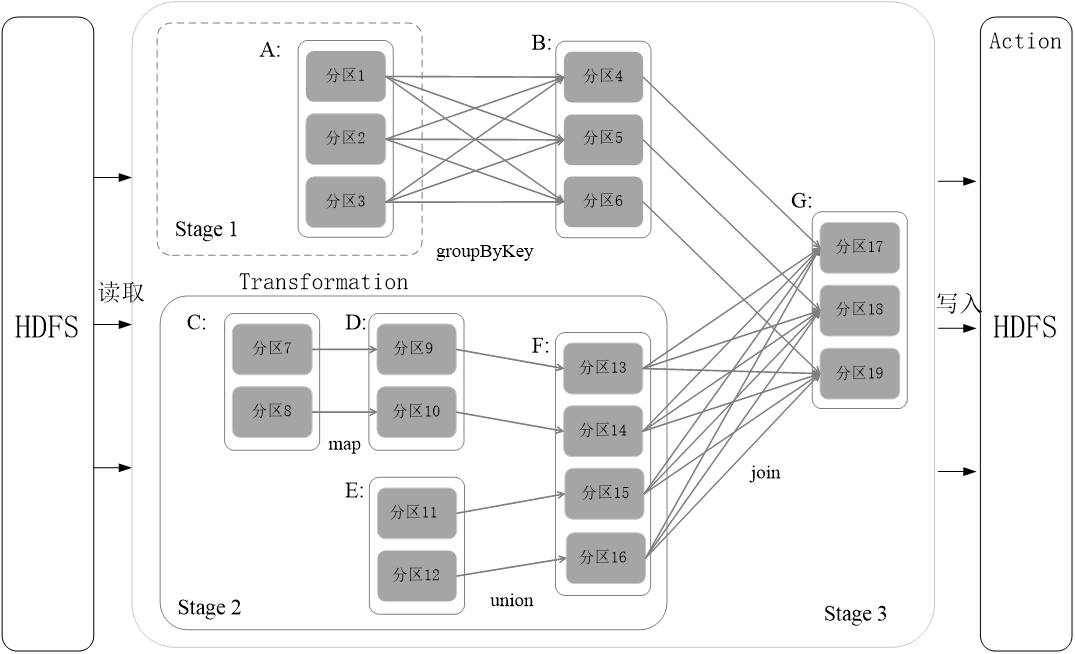
3.4.5 RDD运行过程
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task(Task是Spark中最小的任务执行单元,每个RDD的transformation操作都会被翻译成相应的task,分配到相应的executor节点上对相应的partition执行,RDD在计算的时候,每个分区都会启动一个task,RDD的分区数目决定了总的task数目。),每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
3.5 RDD操作
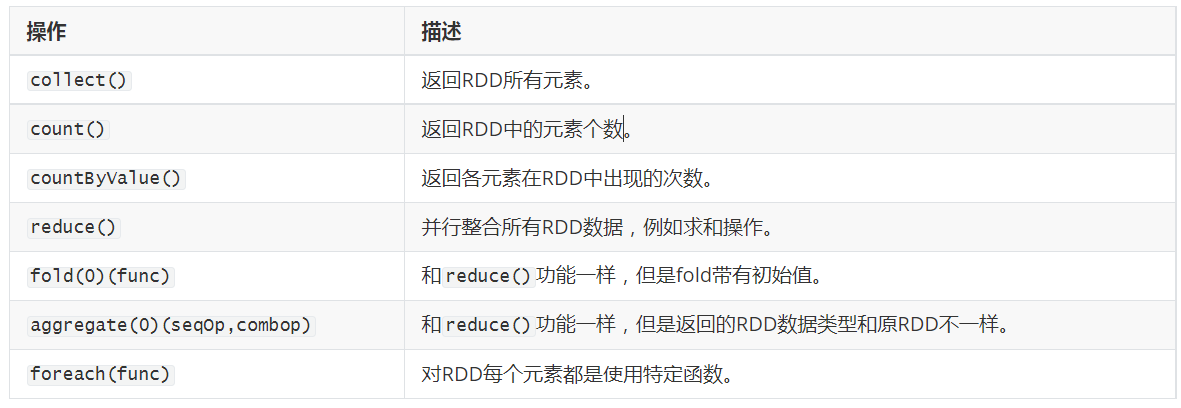
通常,Spark RDD的常用操作有两种,分别为Transform操作和Action操作。Transform操作并不会立即执行,而是到了Action操作才会被执行。详细操作请见RDD APIs
- Transform操作
| 操作 | 描述 |
|---|---|
map() |
参数是函数,函数应用于RDD每一个元素,返回值是新的RDD。 |
flatMap() |
参数是函数,函数应用于RDD每一个元素,拆分元素数据,变成迭代器,返回值是新的RDD。 |
filter() |
参数是函数,函数会过滤掉不符合条件的元素,返回值是新的RDD。 |
distinct() |
没有参数,将RDD里的元素进行去重操作。 |
union() |
参数是RDD,生成包含两个RDD所有元素的新RDD。 |
intersection() |
参数是RDD,求出两个RDD的共同元素。 |
subtract() |
参数是RDD,去掉原RDD里和参数RDD里相同的元素。 |
cartesian() |
参数是RDD,求两个RDD的笛卡尔积。 |
- Action操作
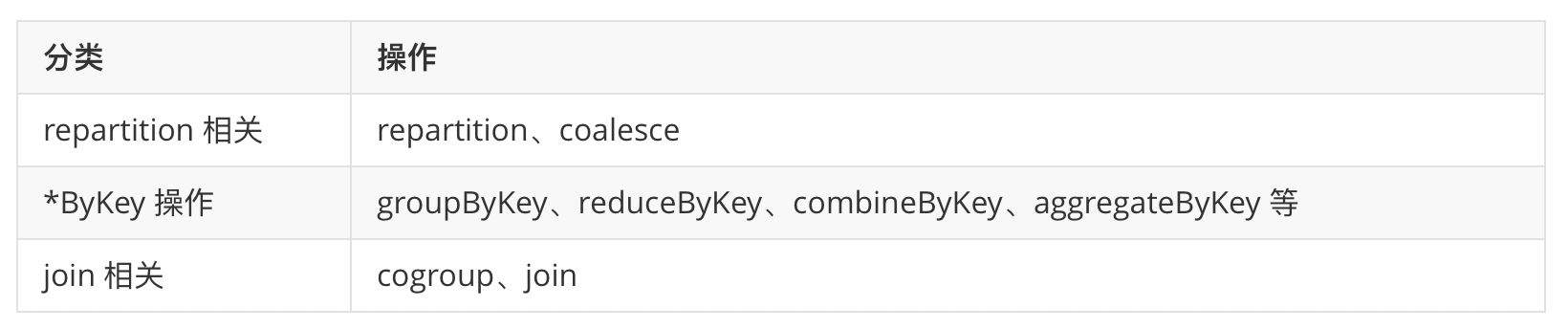
3.5.1 触发Shuffle的操作
会引起shuffle 的操作包括重分区操作(如repartition 和 coalesce)、ByKey操作(除计数外)(如groupByKey和reduceByKey)以及join操作(如cogroup和join)
3.6 RDD分区
RDD中的数据被存储在多个分区中。
3.6.1 RDD分区的特征
- 分区永远不会跨越多台机器,即同一分区中的数据始终保证在同一台机器上。
- 群集中的每个节点包含一个或多个分区。
- 分区的数目是可以设置的。 默认情况下,它等于所有执行程序节点上的核心总数。 例如。 6个工作节点,每个具有4个核心,RDD将被划分为24个分区。
3.6.2 RDD分区与任务执行的关系
[!NOTE|style:flat]
在Map阶段partition数目保持不变。 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
RDD在计算的时候,每个分区都会启动一个task,RDD的分区数目决定了总的task数目。
申请的Executor数和Executor的CPU核数,决定了你同一时刻可以并行执行的task数量。
这里我们举个例子来加深对RDD分区数量与task执行的关系的理解
比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。
[!NOTE|style:flat]
partition数量太少会造成资源利用不够充分。 例如,在资源不变的情况,你的RDD只有10个分区,那么同一时刻只有10个task运行,其余10个核将空转。
通常在spark调优中,可以增大RDD分区数目来增大任务并行度。
[!NOTE|style:flat]
但是partition数量太多则会造成task过多,task的传输/序列化开销增大,也可能会造成输出过多的(小)文件
3.6.3 RDD的分区器(Partitioner)
Spark中提供两种分区器:
Spark包含两种数据分区方式:HashPartitioner(哈希分区)和RangePartitioner(范围分区)。一般而言,对于初始读入的数据是不具有任何的数据分区方式的。数据分区方式只作用于
 HashPartitioner(哈希分区)
HashPartitioner(哈希分区)
HashPartitioner采用哈希的方式对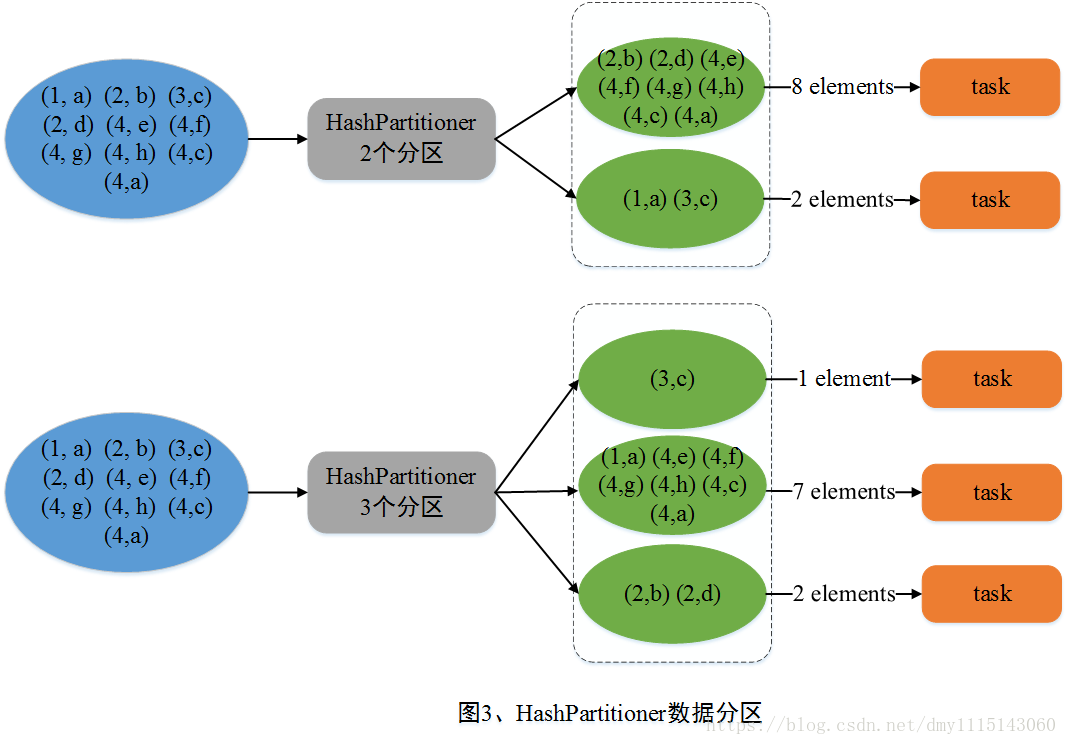
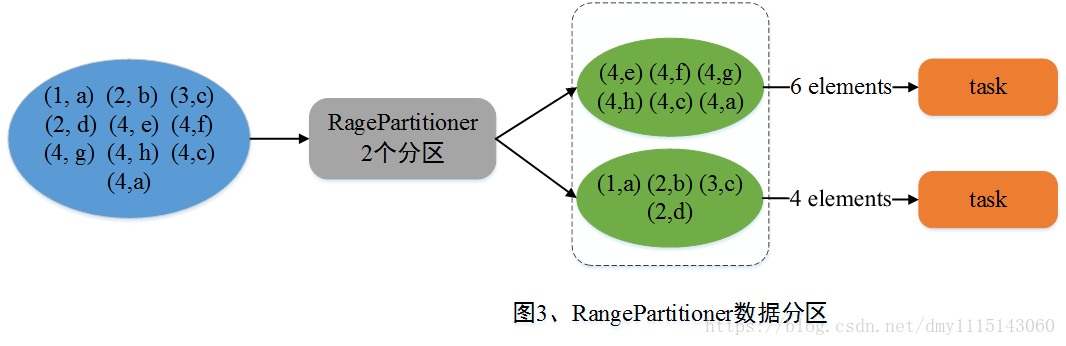
RangePartitioner(范围分区) Spark引入RangePartitioner的目的是为了解决HashPartitioner所带来的分区倾斜问题,也即分区中包含的数据量不均衡问题。HashPartitioner采用哈希的方式将同一类型的Key分配到同一个Partition中,因此当某一或某几种类型数据量较多时,就会造成若干Partition中包含的数据过大问题,而在Job执行过程中,一个Partition对应一个Task,此时就会使得某几个Task运行过慢。RangePartitioner基于抽样的思想来对数据进行分区。图4简单描述了RangePartitioner的数据分区过程。
3.6.4 自定义分区(定义partitioner个数)
案例:对List里面的单词进行wordcount,并且输出按照每个单词的长度分区输出到不同文件里面
//只需要继承Partitioner,重写两个方法
class MyPartitioner(val num:Int) extends Partitioner {
//这里定义partitioner个数
override def numPartitions: Int = num
//这里定义分区规则
override def getPartition(key: Any): Int = {
val len = key.toString.length
//根据单词长度对分区个数取模
len % num
}
}
App的使用:
bject testMyPartitioner {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List("lijie hello lisi", "zhangsan wangwu mazi", "hehe haha nihaoa heihei lure hehe hello word"))
val rdd2=rdd1.flatMap(_.split(" ")).map(x=>{
(x,1)
})
//这里指定自定义分区,然后输出
val rdd3 =rdd2.sortBy(_._2).partitionBy(new MyPartitioner(4)).mapPartitions(x=>x).saveAsTextFile("file:///f:/out")
println(rdd2.collect().toBuffer)
sc.stop()
}
}
四、Spark分布式逻辑回归
Logistic Regression模型的训练过程主要包含两个计算步骤:一是根据训练数据计算梯度,二是更新模型参数向量w。计算梯度(gradient)时需要读入每个样例,代入梯度公式计算,并对计算结果进行加和。由于在计算时每个样例可以独立代入公式,互相不 影响,所以我们可以采用“数据并行化”的方法,即将训练样本划分为多个部分,每个task只计算部分样例上的梯度,然后将这些梯度进行加和得到最终的梯度。在更新参数向量w时,更新操作可以在一个节点上完成,不需要并行化。

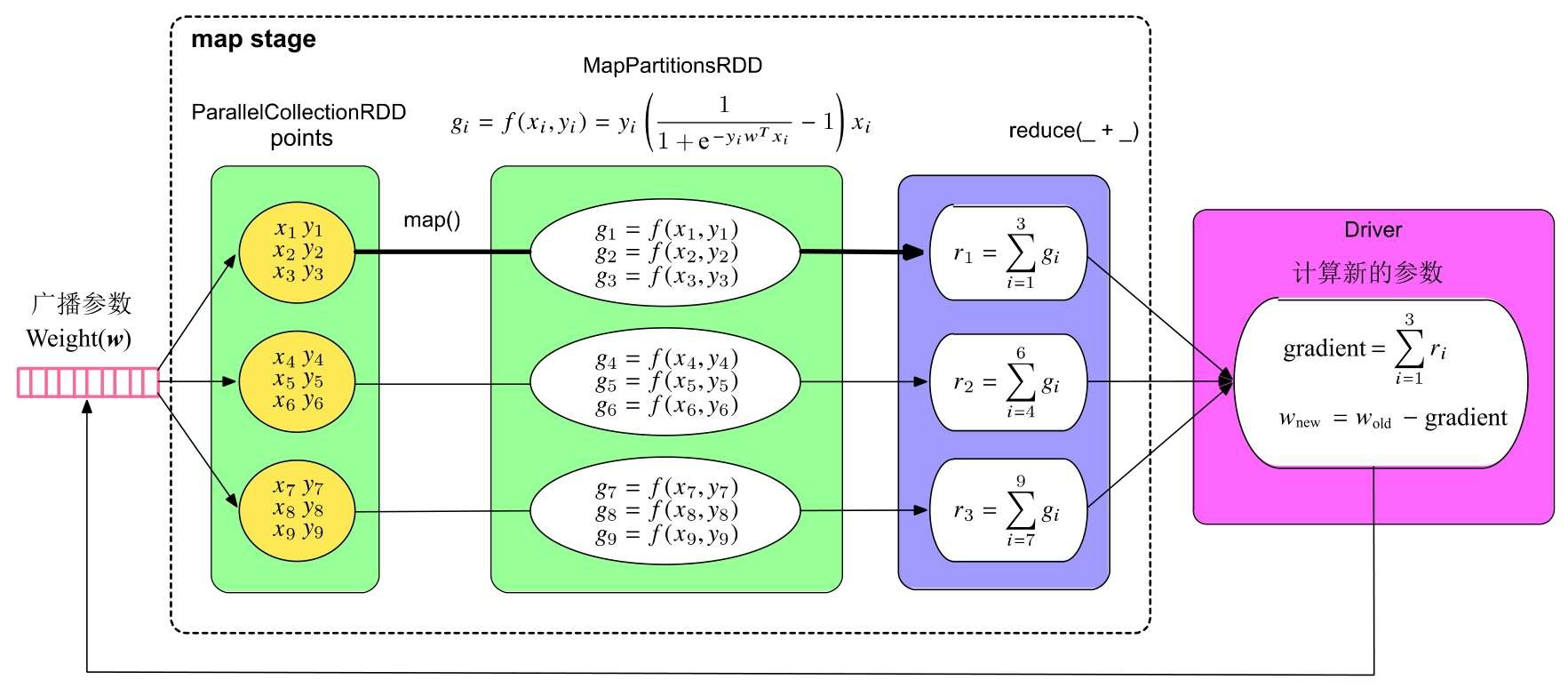
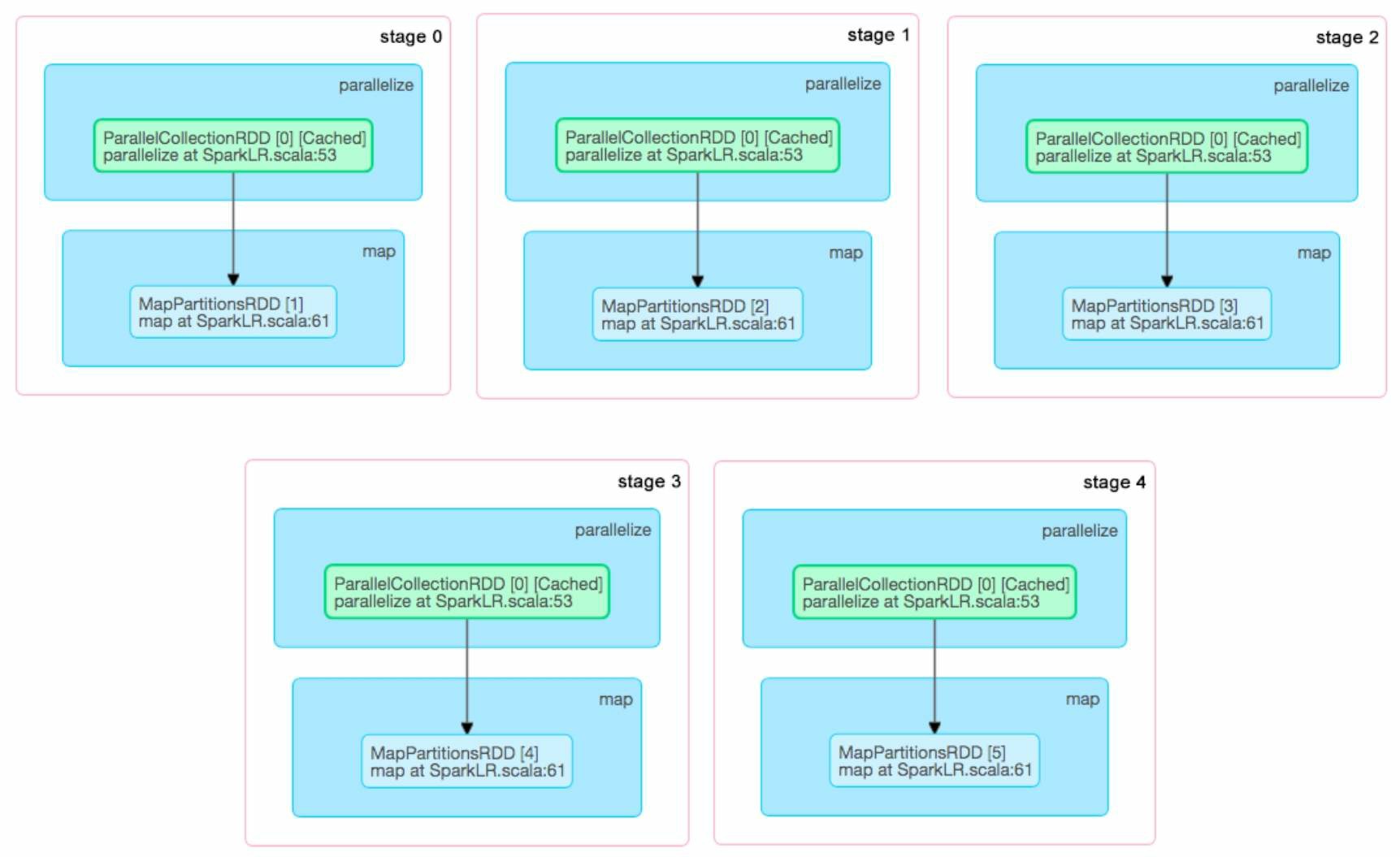
上面我们已经展开讨论了SparkLR的并行化逻辑处理流程,那么,SparkLR在实际运行时生成什么样的job和stage呢?当我们把迭代轮数设为5时,形成的job和stage如图5.4所示。可以看到在这个例子中,SparkLR一共生成了5个job,每个job只包含一个map stage。一个有趣的现象是,第1个job运行需要0.8s(800 ms),而第2个到第5个job只需要56~76ms。发生这一现象的原因是,SparkLR在第1个job运行时对训练数据(points:RDD)进行了缓存,使得后续的job只需要从内存中直接读取数据进行计算即可,这大大减小了数据加载到内存中的开销,从而加速了计算过程。
参考链接
许利杰_ 方亚芬 - 大数据处理框架Apache Spark设计与实现(全彩) (2020, 电子工业出版社)